Abstract
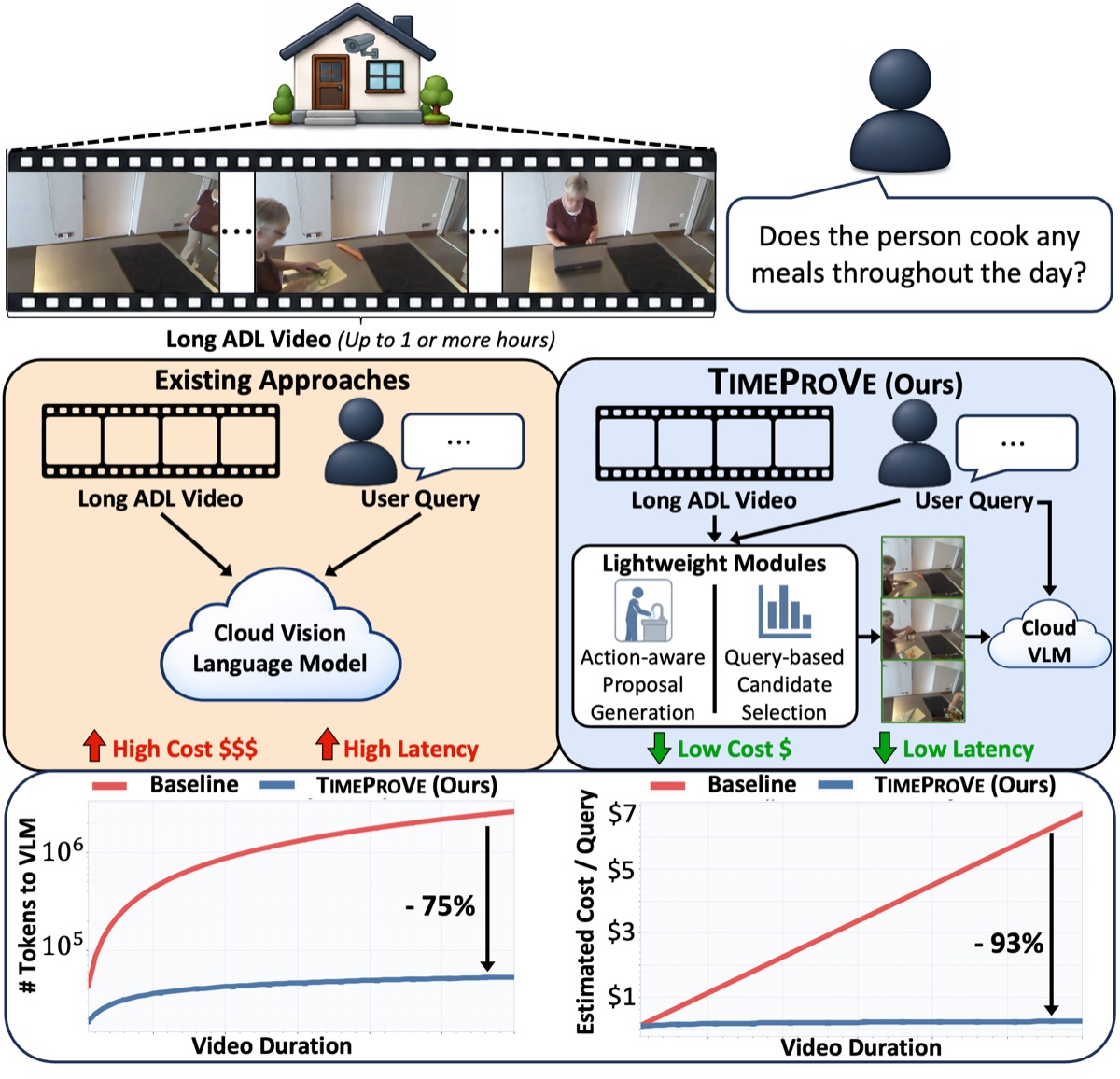
Long Video Question Answering (LVQA) requires identifying sparse, query-relevant evidence within hours-long untrimmed videos. Existing approaches either process videos densely with large vision-language models (VLMs), incurring prohibitive computational cost, or rely on sparse caption-based reasoning, which often misses temporally localized and motion-centric evidence. We introduce TimeProVe, a cost-efficient hybrid framework for temporally grounded reasoning in long videos. TimeProVe first employs lightweight modules to generate action-grounded answer--evidence hypotheses and subsequently invokes an expensive VLM only for targeted verification. The core of our framework lies in the Action-based Candidate Evidence (ACE) module, which converts temporally localized actions into query-conditioned candidate answers and supporting evidence windows through lightweight LLM reasoning. We further introduce OpenTSUBench (otb), an open-ended benchmark designed to evaluate temporally grounded reasoning in real-world Activities of Daily Living (ADL) scenarios. Experiments show that TimeProVe outperforms the strongest baseline on otb by 7.3%, while reducing VLM calls by 75% and inference cost by 93%. Furthermore, without explicit temporal grounding training, TimeProVe achieves competitive performance on Charades-STA, and reaches state-of-the-art results when enhanced with grounding VLMs.
TL;DR
Use lightweight modules to propose candidate answers paired with temporally localized evidence windows.
Verify only the most promising candidates with a VLM, drastically reducing the number of expensive calls while preserving temporally grounded reasoning.
TimeProVe framework
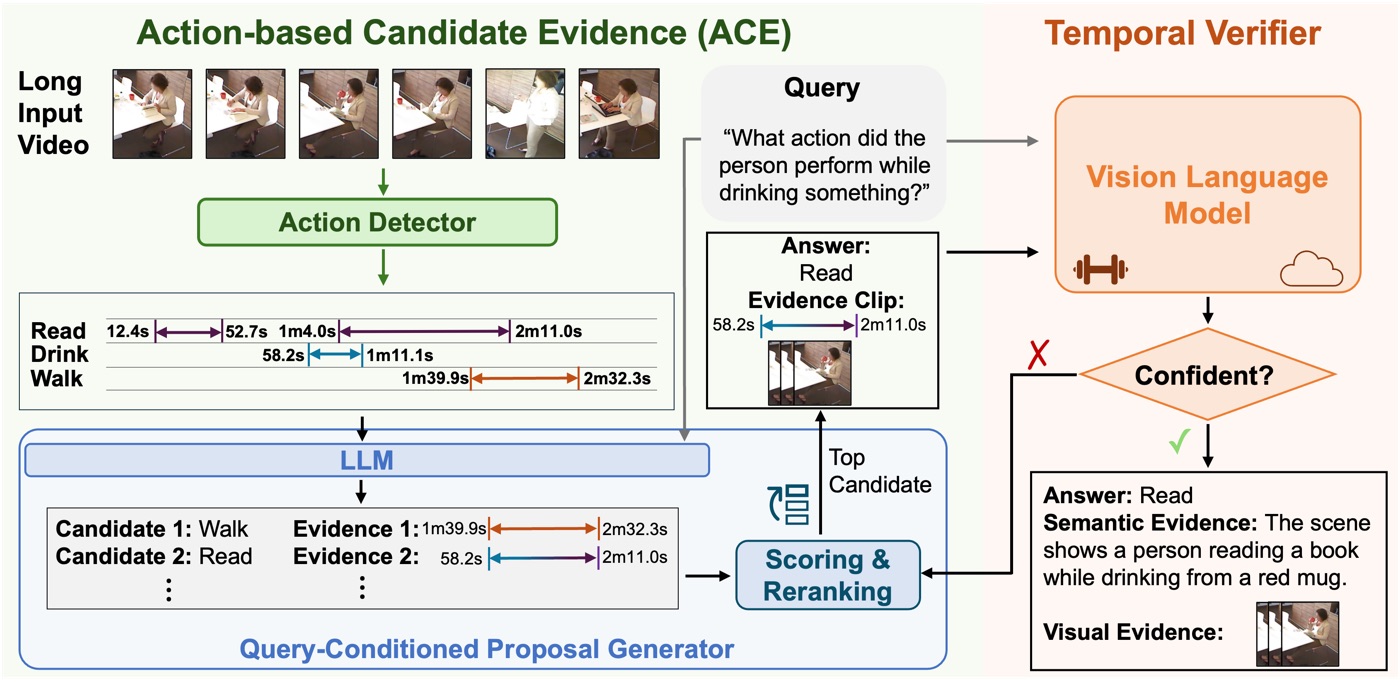
ACE first builds an action timeline from the full video, then uses query-conditioned proposal generation and reranking to produce candidate answer-evidence hypotheses. A temporal verifier sends only the top short RGB clip to a VLM for confirmation, iterating to the next candidate only when needed, which preserves temporal grounding while substantially reducing expensive full-video inference.
OpenTSUBench (otb)
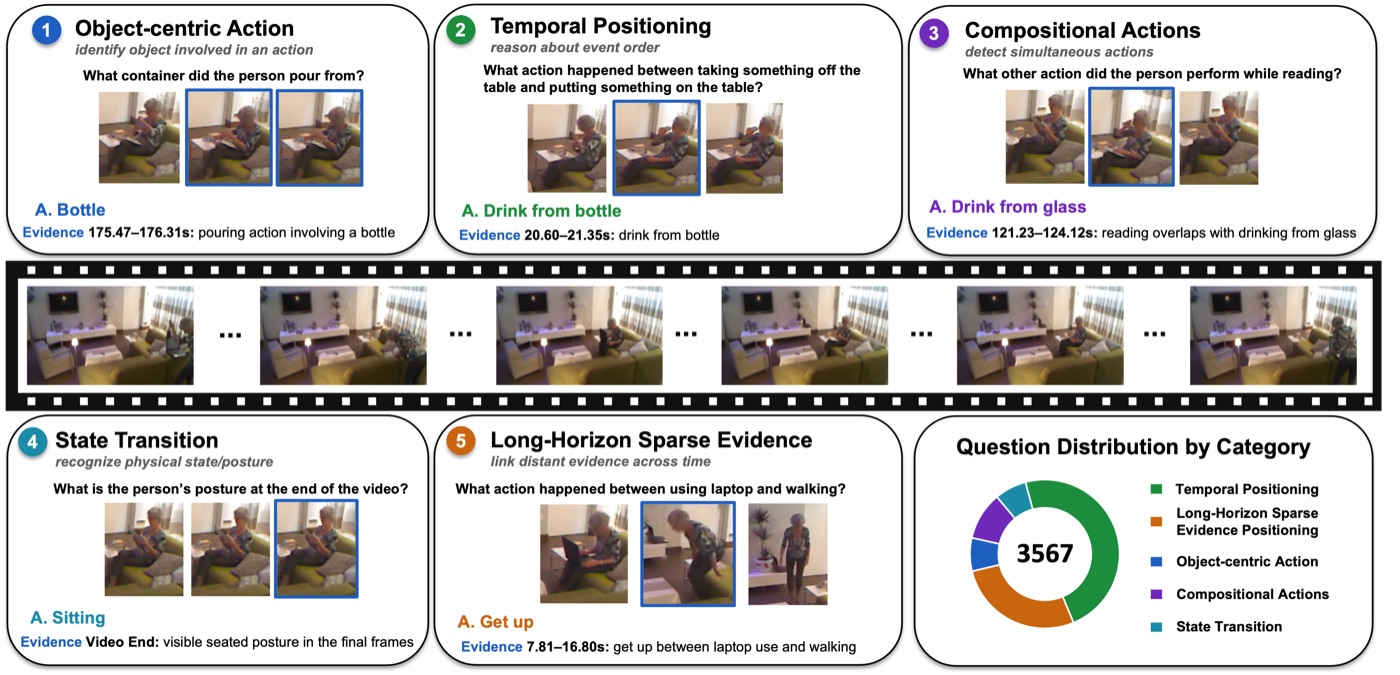
OpenTSUBench is an open-ended, temporally grounded LVQA benchmark for real-world untrimmed ADL videos, where each question is paired with supporting temporal evidence. It includes diverse strata such as temporal positioning, long-horizon sparse evidence, object-centric actions, concurrent activities, and state transitions to evaluate both answer correctness and evidence localization.
Qualitative Examples
TimeProVe localizes sparse temporal evidence from a long ADL video and verifies query-relevant clips using a VLM, avoiding full-video processing.
BibTeX
@misc{sinha2026timeprove,
title={TimeProVe: Propose, then Verify for Efficient Long Video Temporal Reasoning in Activities of Daily Living},
author={Arkaprava Sinha and Dominick Reilly and Siddharth Krishnan and Hieu Le and Srijan Das},
year={2026},
eprint={2606.20561},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2606.20561},
}