I am a Graduate Research Assistant pursuing a Ph.D. in Computer Science at the University of North Carolina at Charlotte, advised by Prof. Srijan Das. My research lies at the intersection of multimodal vision-language models, long-context video understanding, temporal modeling, and agentic systems, with a focus on building scalable and reliable algorithms for long video understanding.
Prior to my Ph.D., I worked as a Data Scientist, contributing to projects in computer vision, natural language processing, and large-scale machine learning across industry and research settings.
Research
I build efficient multimodal AI systems that can understand and reason over long, untrimmed videos of everyday human activity.
My research focuses on building efficient multimodal AI systems for long-horizon video understanding, egocentric perception, and visual reasoning. I design scalable temporal architectures and representation-learning methods that help models reason over long, untrimmed videos, align video with language, motion, and structured visual cues, and operate efficiently in real-world settings.
I am particularly interested in agentic video understanding, where systems actively search for relevant evidence, reason over temporal context, and verify answers using multimodal foundation models instead of exhaustively processing entire videos. Broadly, my work connects long video understanding, vision-language models, multimodal LLMs, diffusion-based generation, and embodied AI — with applications in robotics, AR/VR, intelligent assistants, assistive technology, and safety-critical video analytics.
News
Feb 2026
MS-Temba accepted to CVPR 2026.
Feb 2025
LLAVIDAL accepted to CVPR 2025.
Dec 2024
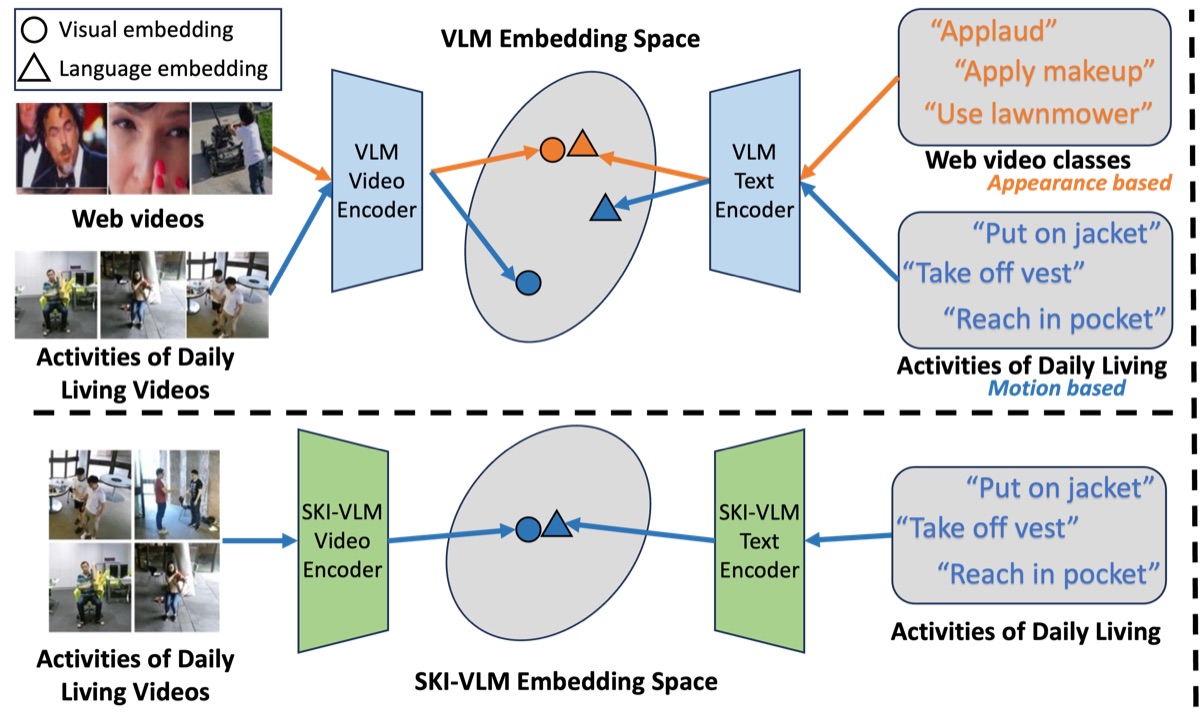
SKI Models accepted to AAAI 2025.
Oct 2024
2 papers accepted to NeurIPS 2024 workshops; an early version of LLAVIDAL presented at the NeurIPS 2024 Workshop on Video-Language Models and Multimodal Algorithmic Reasoning.
Arkaprava Sinha, Dominick Reilly, Siddharth Krishnan, Hieu Le, Srijan Das
Preprint, 2026
A hybrid long-video reasoning framework that proposes action-grounded hypotheses efficiently, then verifies only sparse RGB evidence with an expensive VLM.
Wenhao Chi, Arkaprava Sinha, Dominick Reilly, Hieu Le, Srijan Das
Preprint, 2026
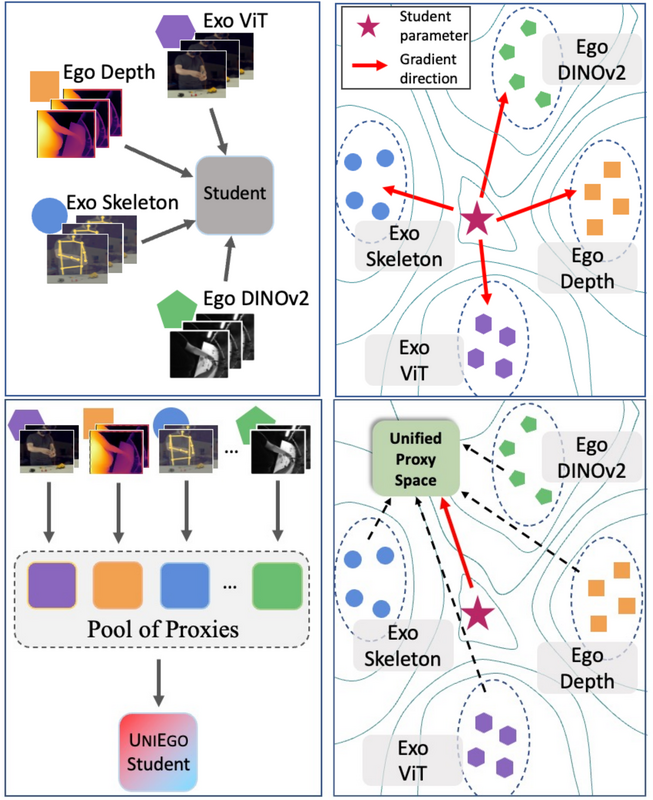
A unified egocentric encoder trained via hierarchical distillation across ego-exo viewpoints, modalities, and foundation models, using representation-specific proxies as mediators.
Dominick Reilly, Rajatsubhra Chakraborty, Arkaprava Sinha, Manish Kumar Govind, Pu Wang, Francois Bremond, Le Xue, Srijan Das
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
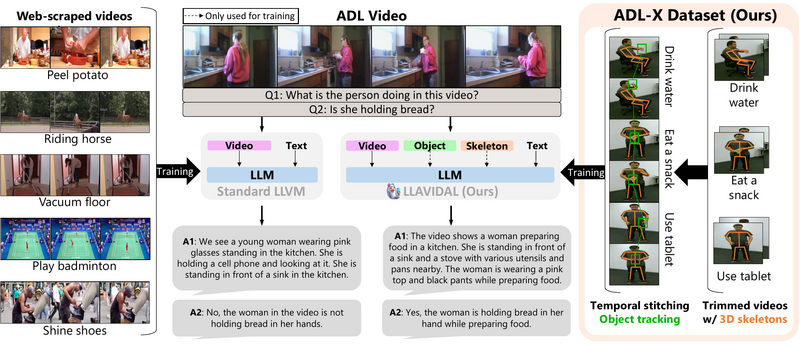
A large language-vision model that incorporates 3D poses and object trajectories to understand the spatiotemporal relationships within daily living activities.